ABCs of data science is intended for anyone who wants to learn more about data science, regardless of skill level. It aims to give readers a high level overview of various data science concepts, so that they can explore these topics further. Note that these blogs were written before the explosion of LLMs but should hopefully provide some intuition into other data science techniques.
data_science
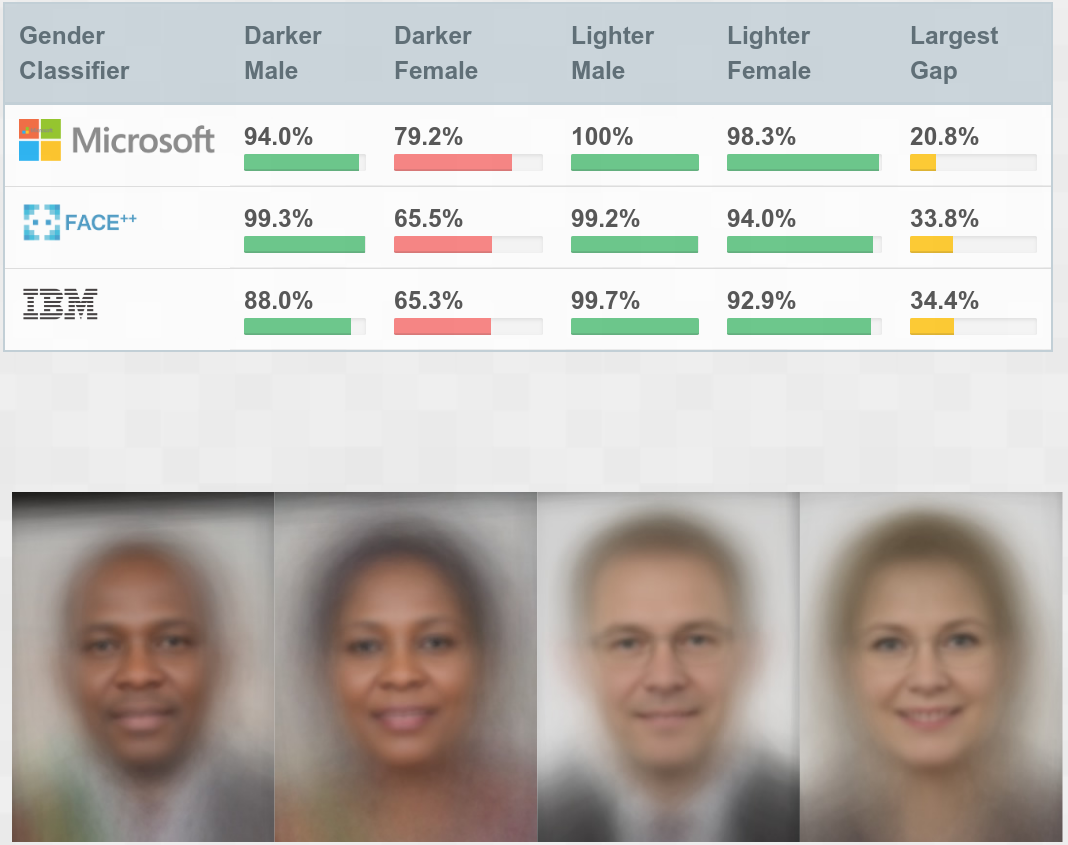
bias
interpretability
data_science
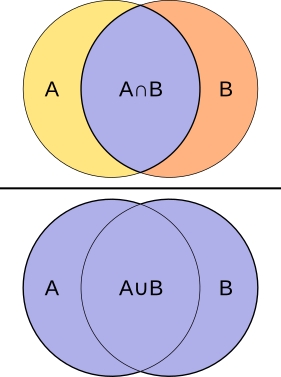
clustering
unsupervised_learning
data_science
deep_learning
supervised_learning
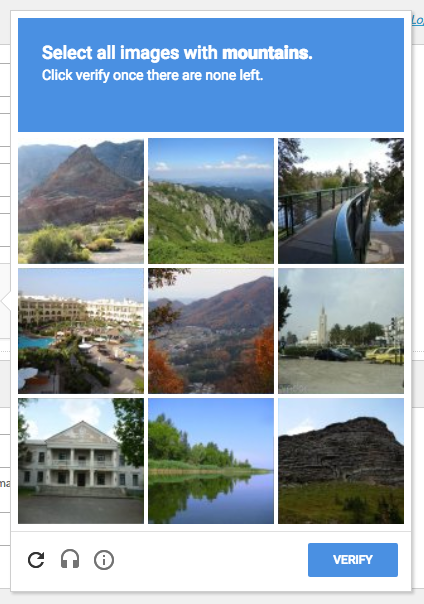
AI
data_science
embeddings
unsupervised_learning
AI
data_science
metrics
supervised_learning
AI
data_science
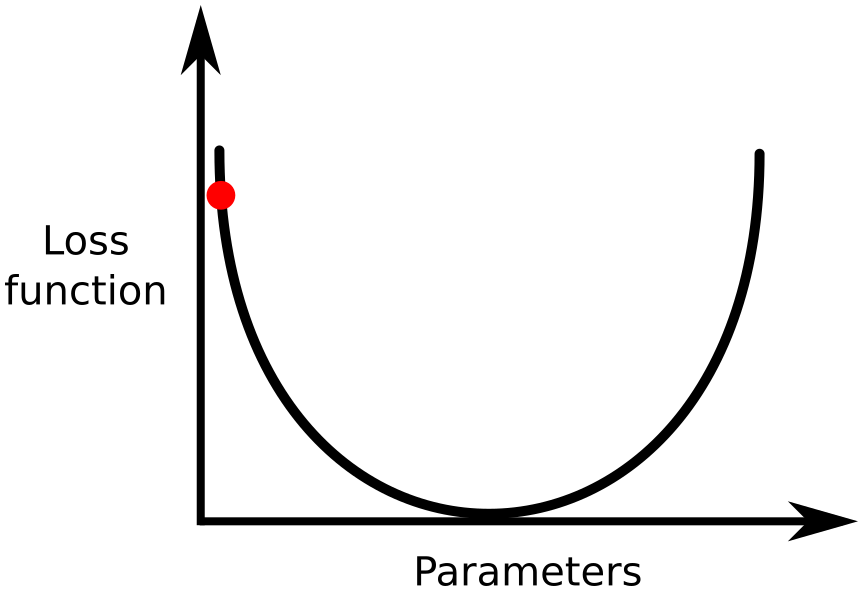
optimization
supervised_learning
AI
data_science
clustering
unsupervised_learning
data_science
supervised_learning
AI
bias
data_science
embeddings
distance_measures
data_science
supervised_learning
AI
data_science
supervised_learning
AI
data_science
data_cleaning
data_science
nlp
text_processing
data_science
unsupervised_learning
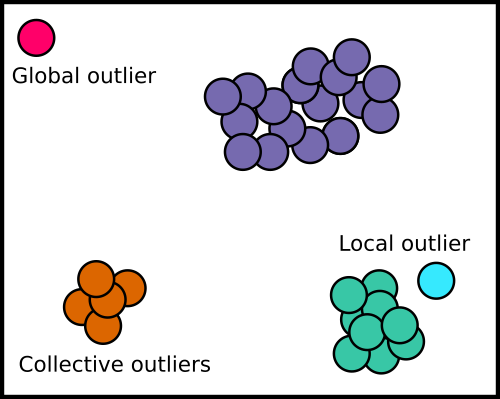
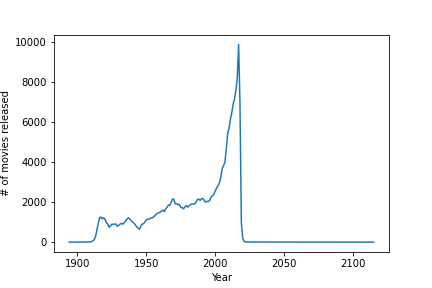
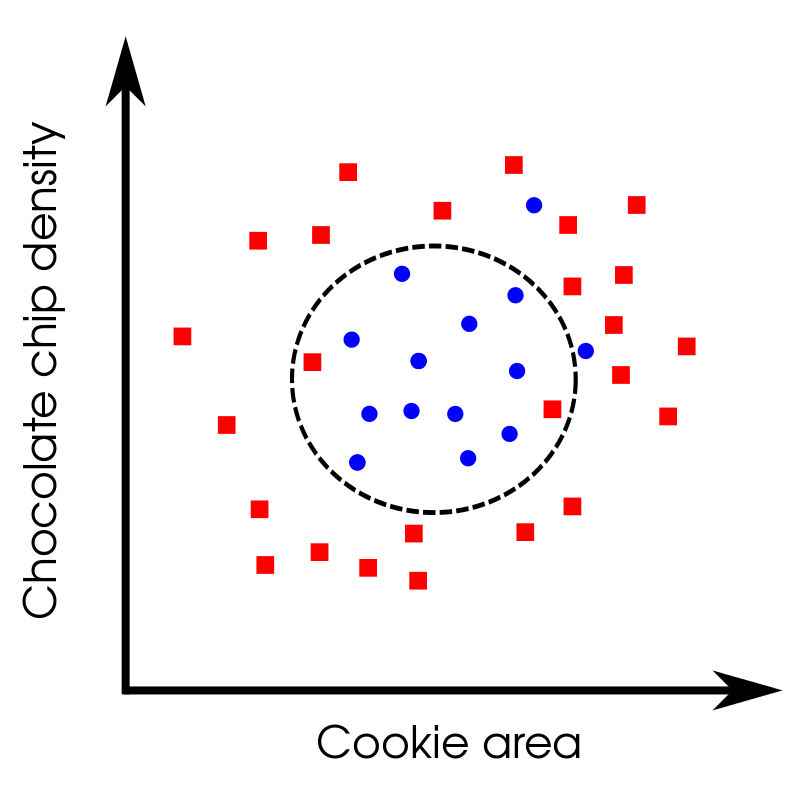
anomaly_detection
data_science
data_cleaning
data_exploration
data_science
reinforcement_learning
data_science
reproducibility
data_science
supervised_learning
random_forest
deep_learning
data_science
supervised_learning
pretrained_models
data_science
embedding
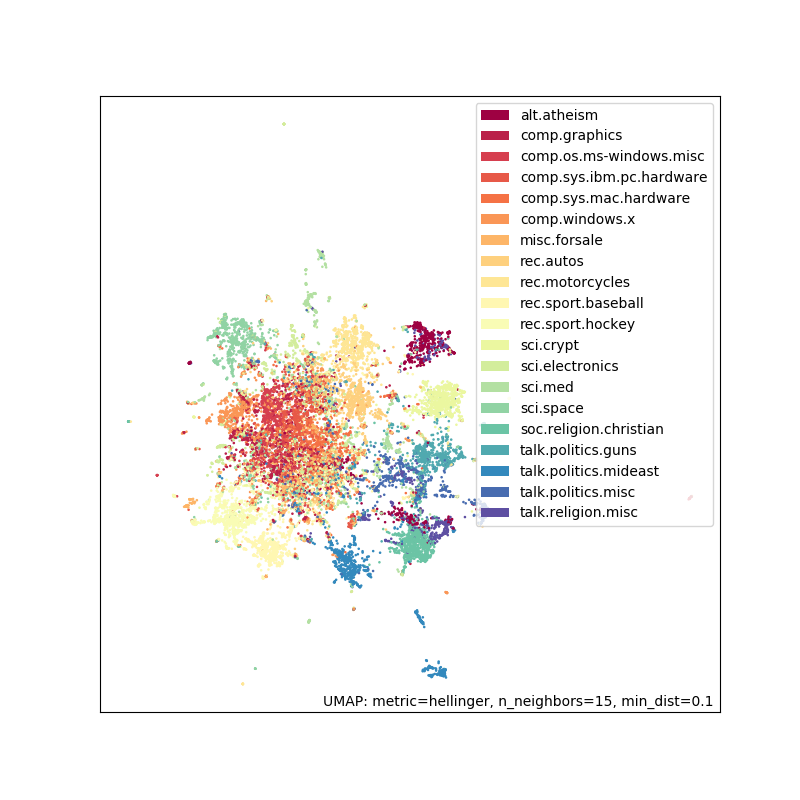
dimension_reduction
data_science
visualization
plotting
data_science
synthetic_media
gans
deepfakes
data_science
supervised_learning
xgboost
ensembles
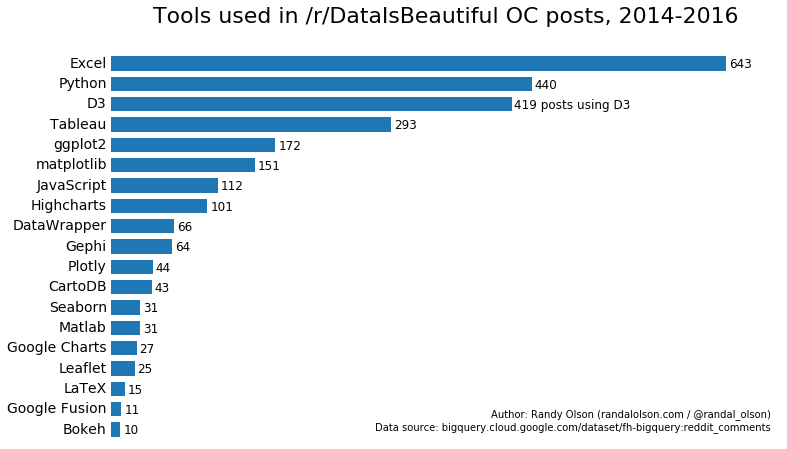
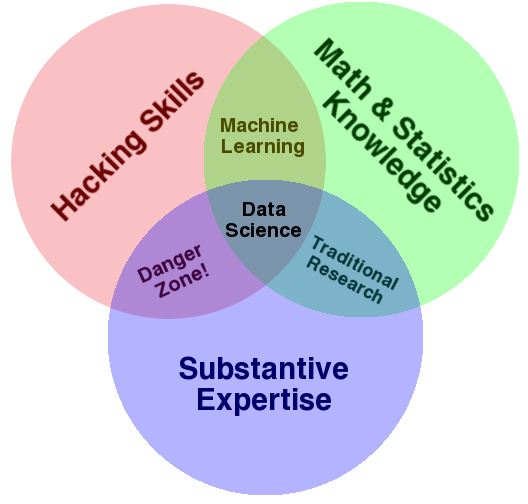
No matching items